Model capabilities improve over time, but open-weight models lag the frontier
I often ask Claude mundane questions about cooking, fitness, and cars, among other things, and I can’t say I’ve found Fable 5 to be some magical step change vs. previous Claude models (e.g., Opus 4.7) at answering my day-to-day questions. I was already in awe of the fact that for $20/month I can have functionally unlimited access to incredible intelligence in my pocket; Fable 5 may be smarter, but it’s probably not going to help me plan a date night dinner any better. There are diminishing marginal returns to intelligence; the majority of my (and probably most consumers’) day-to-day AI usage isn’t going to really benefit from a smarter model.
Let’s shift focus to the enterprise. There’s a vast array of jobs to be done and people to do them: lawyers and executive assistants and nurses and customer service workers and account managers and accountants. Seriously, there is a LOT of white-collar work being done today in the US. You could imagine some tier-system that bucketed these types of work into difficulty levels: manual data-entry would probably be pretty low on the list; (some) work done by biology researchers or lawyers or software engineers would probably be higher up on the list.
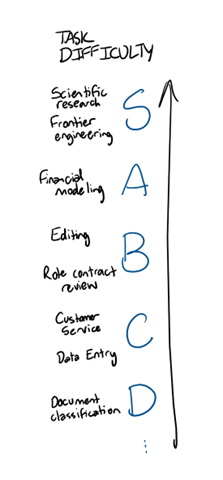
But the same law of diminishing marginal returns applies: beyond a certain point, hiring a smarter-than-necessary human doesn’t really improve performance. And if you wanted to augment or automate this labor – diminishing marginal returns applies to model intelligence also. But again, there’s a diversity of tasks, and new models can continue to push the frontier forward for some while not being materially better on others. Fable 5 is clearly a gamechanger for hardcore software engineering and beating Pokemon; I haven’t seen notable performance improvements in my Chipotle burrito-bowl ordering workflow.
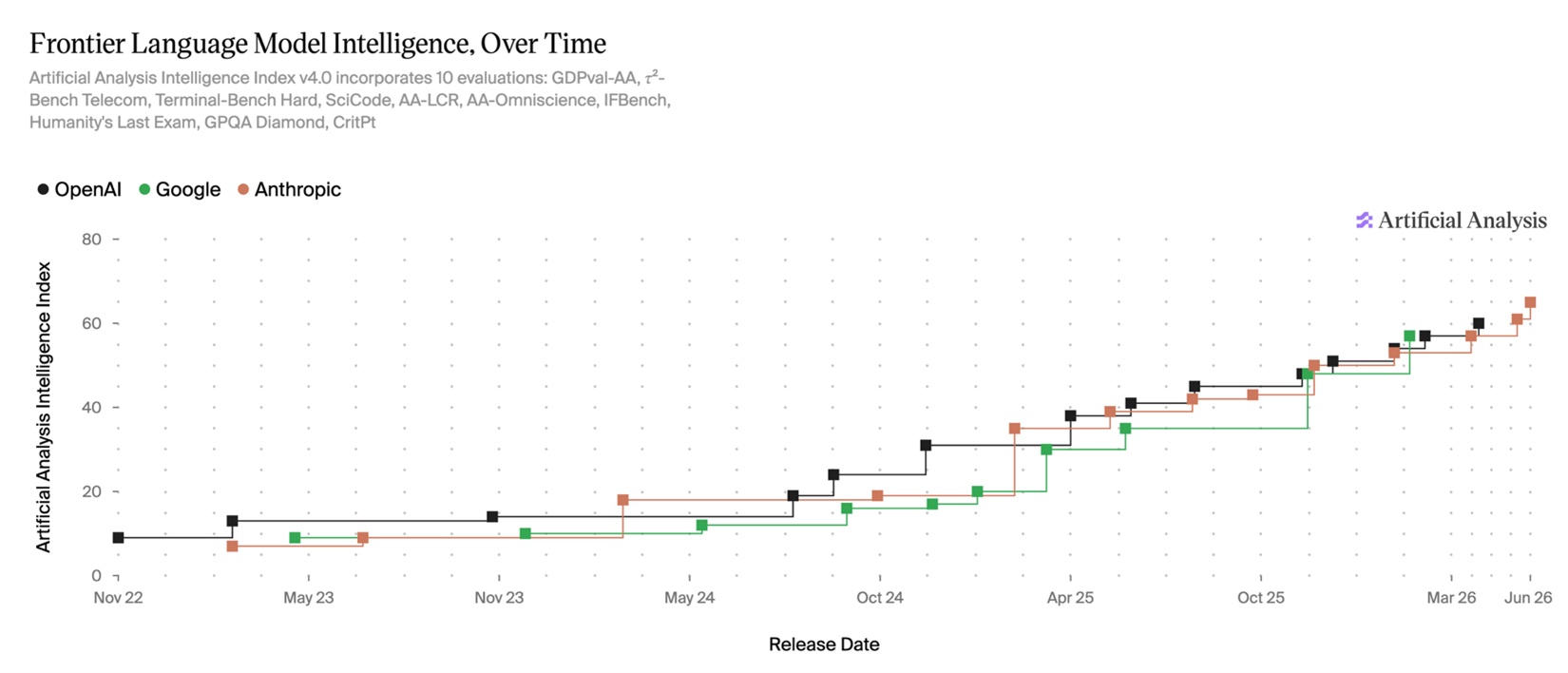
The Artificial Analysis Intelligence Index v4 (AAII) measures model performance across a variety of domains; it’s an “index fund of benchmarks” in a sense. No evaluation is perfect, but for the purposes of this discussion, this feels like the most useful one. I also like the Epoch Capabilities Index.
Model performance has only improved over time, and I see no reason why it shouldn’t continue to improve in the future. Let’s turn our task difficulty tier list into a y-axis and show model performance over time. This is just illustrative; a precise mapping from AAII score to capabilities on real world tasks is unclear, and I’m not trying to make a prediction that doctors or lawyers or software engineers will be automated by 20XX. I’m merely saying that (1) the frontier models have gotten better over time, that (2) they’ll probably continue to do so, and that (3) as they get better and better, more and more tasks will reach the asymptote for diminishing marginal returns to model intelligence.
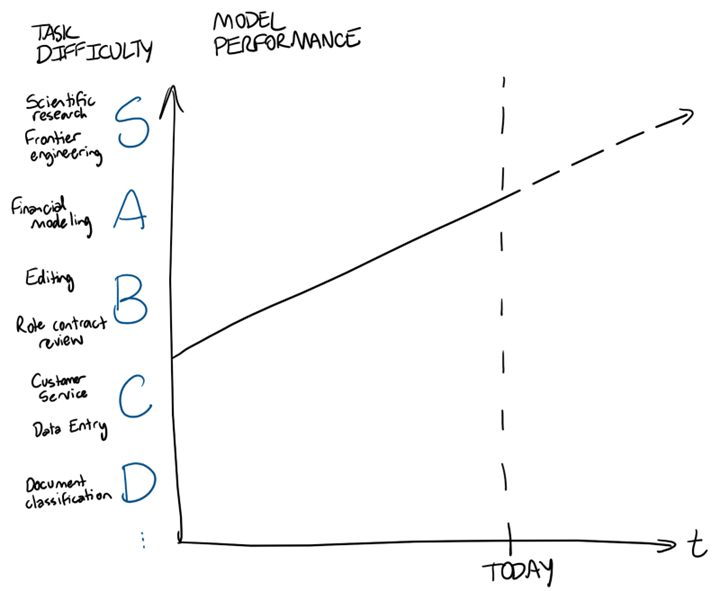
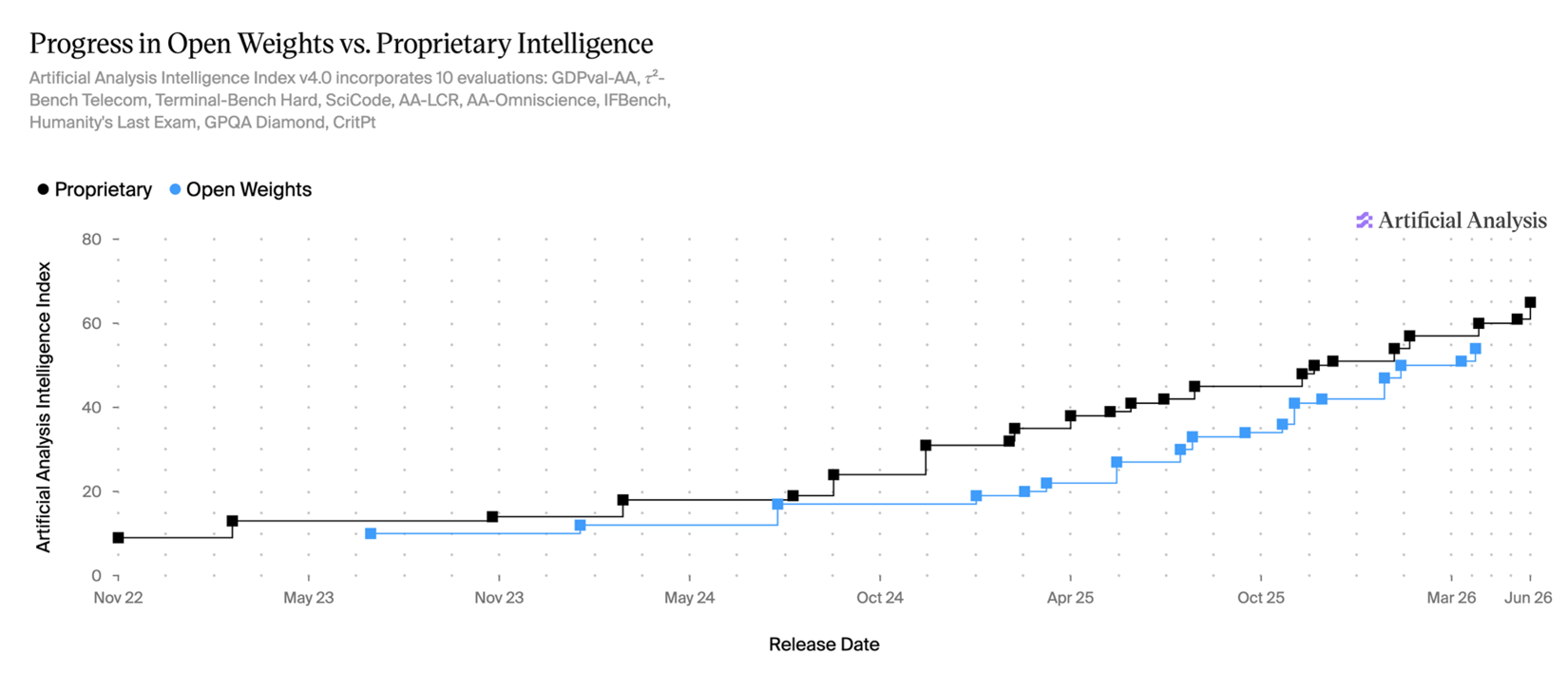
Behind the frontier lies open-weight models: models that theoretically anyone could run with the right compute hardware. Open-weight models are usually substantially cheaper vs. models from Google / Anthropic / OpenAI, but are also less intelligent. How far behind open-weight models are vs. the frontier is up for debate, but for now let’s assume the answer is ~4 months or so on benchmarks [1].
Open-weight models also come in a variety of sizes. For example, the Gemma 4 family of open-weight models from Google comes in E2B, E4B, 12B, 26B A4B, and 31B sizes. Understanding the alphabet soup isn’t important, but larger models (more parameters) typically correlates to more intelligence, while smaller models can run on smaller and less expensive devices (e.g., phones, laptops). Let’s add two more lines to our graph above: one for the cutting edge of open-weight models, and another for what could feasibly run on an average laptop.
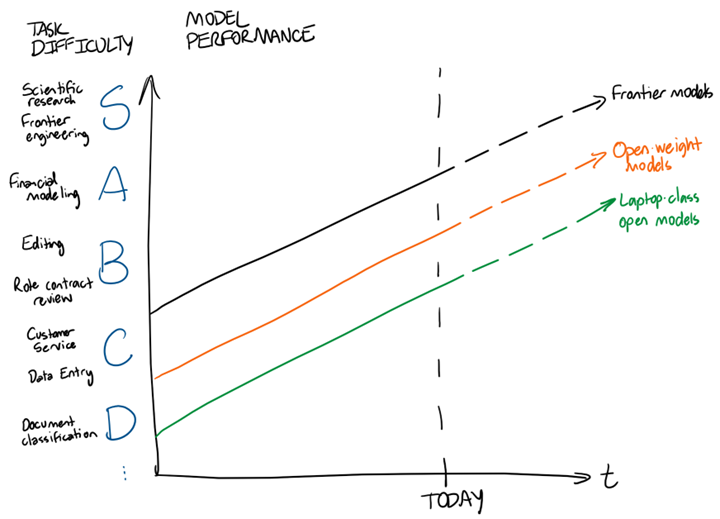
When will these laptop-class open-weight models reach today’s frontier capabilities?
When should we expect to see a model at the level of Fable 5 that’s small enough to run on today’s run-of-the-mill MacBook Air? My predictions are in the table below: each row represents a different model capability level, and each column represents how much RAM a specific device (e.g., a laptop) would need. Today, $1,000 gets you a machine in the leftmost column, and $5,000 gets you something in the rightmost column – I haven’t factored in any progress on the laptop side of things, and that alone makes this a conservative estimate, but I also think that the timelines in the table below could accelerate even more if the rate of progress picks up (and lately, it has). Note that these timelines are for performance parity on benchmarks; real-world performance parity likely will lag by another 6-12 months or so.
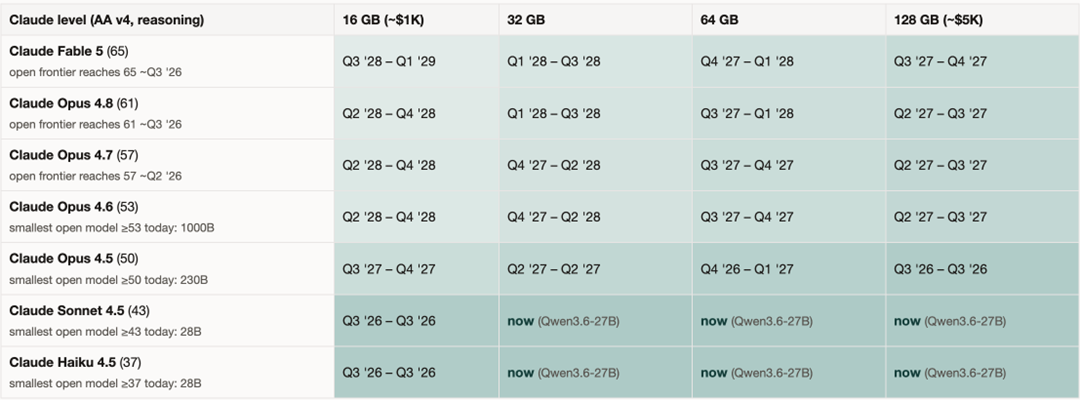
If you’re interested in how I arrived at these numbers, you can find a full analysis here (download the file and open it in Chrome), and the full data and Python scripts behind it here.
What does Fable 5 being diffuse throughout the economy entail?
I doubt consumers will care much about running on-device models. ChatGPT Free-tier consumers probably don’t care about having access to the smartest models and probably aren’t running into rate limits all that often; they probably do care about ease of use (not having to set anything up), a strong memory system, and access to multimodal outputs (image generation has clearly caught on with the consumer crowd). Seeing ads here and there won’t be much of a turn off (see: Instagram, Google Search). Paid consumers probably won’t care much about on-device models either: if you care about model intelligence, you’re sticking with the closed-weight frontier, if you care about rate limits, I imagine a more built out ads engine can solve that (would you rather wait for your limits to reset, or press on with ads if the option were presented to you?).
It’s a different story in the enterprise. Excluding FOMO-driven tokenmaxxing, enterprises make decisions by looking at basic ROI calculations, and if the 90th percentile of businesses are spending $7200/year/employee on AI spend [2], there’s going to be a pretty strong incentive to switch over to an open-weight model that costs ~20% of that or to a local model that’s free. The unknowable trillion-dollar-question is for what workloads frontier models will continue to command positive ROI over their open-weight and local counterparts. I can see a world where frontier models continue to be worth their price in fields like life sciences, healthcare, finance, law, and engineering (whether physical or digital) over the next handful of years. I also can see a world where e.g., Opus 5.5 is good enough for the vast majority of tasks done in the vast majority of enterprises, and companies that run the numbers conclude that buying every power user a ~$5,000 laptop with an RTX Spark inside is the right capex-opex tradeoff.
And though I hate to end on a sour note, anyone having easy (I took me 30 minutes and 4 prompts to get Claude to install an open weight model on my machine) access to the cybersecurity capabilities of a Mythos-class model is certainly a terrifying thought. Sufficiently empowered, just one bad actor can ruin a lot of people’s day.
[1] Note that on-paper performance ≠ real-world performance, especially for open-weight models. Open and closed-weight models have fundamentally different incentive structures; open labs are empirically more prone to “benchmaxxing” (inflating benchmark numbers relative to real-world performance) vs. closed labs which sell model usage. Nathan Lambert (a massive proponent of open-weight models) specifically calls out the AAII for under-estimating the real-world gap in model performance. Therefore, every "Claude-level by date X" estimate in this post should be read as benchmark-score parity; practical parity on messy, real-world work typically comes down the line (roughly ~6-12 months later).
[2] Note that Ramp customers are probably skewed toward higher-growth.