Here’s another group project I did, this time with Kaila Prochaska, Michael Sullivan, Rish Bhatnagar, and Matt Macdonald for our Data Science Principles class. It’s all about predicting the outcomes of regular season NBA games. You can view the presentation that was associated with it here, and associated files (e.g. code, data, etc.) here.
background
Our goal is to predict the winner of an NBA game, and hopefully well enough that we can make money in Vegas. The betting markets for the NBA are vast - for any given game, there are markets on the winner, the point spread, the total number of points, the total number of points in the second half…
While we don’t consider ourselves smarter than the rest of the betting markets, we did hypothesize that it might be possible to obtain an edge - while we doubt the ability to profit off of “smart money” - those making bets using data science techniques, it’s possible that the “dumb money” of fans looking to emotionally and financially invest into a game may be profitable. Fans may be tempted to bet on teams even when the bet isn’t all that attractive; we hoped that we could be beating these market players.
For better or worse, this is a problem that many have tried to solve. We found some excellent blog posts from the usual suspects (such as FiveThirtyEight) and some unexpected sources (even StitchFix’s blog features an article!). As we’ll discuss later, however, even Vegas hasn’t been able to crack the prediction code yet.
the data
We obtained most of our game and player related data from this Kaggle competition. We also obtained betting data (e.g. Vegas moneylines) from this website. Data was also verified using basketball-reference.com (which FiveThirtyEight also uses). The data includes basic information for each game from the 2003-04 season onwards, such as the final score, the home team and away team, the date played, and other basic performance information such as rebounds, assists, and 3 pointer percentage among others - admittedly, we mostly ignored this information, due to concerns of lookahead bias. It also included information on each players’ plus/minus stats, a measure of an individual player’s effectiveness (a good explanation can be found here).
Betting data was available from the 2007-08 season onwards, and for each game we were able to obtain a moneyline for both the home and away teams. From the moneylines, we calculated a “breakeven win percentage” [1] for both the home and away teams: essentially, it answers “Above what win probability does this moneyline bet become profitable?”
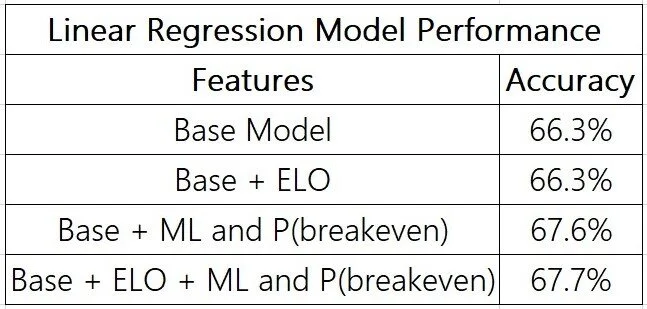
We also augmented the dataset with a few additional features. Hypothesizing that back games back-to-back (on consecutive days) may hinder a team’s performance (players might be tired), we added in “B2B_home” and “B2B_visitor” to our dataset. Next, we also decided to add in each team’s the current season’s record (the number of games played, wins, and losses). We added in information on a team’s ELO rating (more on that below) and the predictions outputted by the ELO model, and the average of the home and away teams’ plus/minus when playing at home and on the road.
As previously mentioned, lookahead bias became a large concern as we worked with our data - we didn’t want to use data from the game itself to generate a prediction for that game. Thus, for each game we limited the data available by asking “What information was available at tipoff?” We decided to throw out the data on rebounds and assists and shooting percentages for this reason, and we also had to re-do the season records for each team due to the same issue. We also extended this lookahead bias mitigation to testing our models: we reserved the 2018-19 and 2019-20 seasons for testing, and only trained on information before that. These steps helped ensure the validity of our results.
evaluation
We used two different metrics to evaluate the results of our models. The first, accuracy, is simple: it measures the percentage of games we properly predicted. Each model outputs a “soft prediction” for each game - the probability it assigned to the home team winning. We thresholded these values at 50% (so if the home team had higher than a 50% probability of winning the game, we called it in favor of the home team, otherwise we ruled for the away team). However, while accuracy is simple and easy to understand, it doesn’t account for “market expectations” - essentially, it’s more difficult to call a tossup than it is to call an obvious blowout, yet we value each call equally.
As a result, we decided to incorporate the betting data we had available to create a “profitability” metric that would measure how much money we would be able to make against Vegas [2]. This metric does account for market expectations, though there’s certainly more complexity in our betting strategies: When do we make a bet? And how much do we bet? We decided to create some arbitrary threshold we’ll call “minimum opinion difference”, that basically measures the difference between our soft prediction for each team (the likelihood we assign to a team winning) and the “breakeven win probability” as described above. Whenever that difference is sufficiently large for either team, we’ll make a bet. We arbitrarily chose to use 6% as the threshold - perhaps future work could uncover an optimal setting. On the bet sizing front, we came up with three strategies, described below.
Always Bet $100.
Favor Favorite: When we’re betting on the favored team, bet enough to profit $100 off of the bet. Otherwise, bet $100.
Bet Proportionally: If our opinion difference is X times the min opinion difference parameter, bet $100 times X. As an example, if we predicted the home team to win with 78% accuracy and had a breakeven win probability of 66%, our opinion difference is 12%. That’s twice the threshold, so we’d bet $200.
Ultimately, the Bet Proportionally strategy always returned terrible results, so we didn’t report those results here - it’s apparent that we’d never actually use this strategy. This is likely because when models make truly far-out predictions, the penalties are far higher - we’re betting much more on the predictions that are the furthest away from market consensus.